Since 2012, the amount of compute in the largest machine learning training runs has been doubling every three and a half months: the deployment of the state-of-the-art developments is expensive. With the slow, hard to scale inference, compression techniques like knowledge distillation become key in realizing the full potential of these models on low-power platforms.
Knowledge distillation helps reduce the lag and size of applications from lane detection and steering to semantic segmentation and pose estimation by teaching the lighter model mimic the output and internal data representations of the parent model.
TensorFlow.js makes using machine learning in the browser and Node.js easy, providing the tools to convert and optimize existing models in Python or to develop new ones in JavaScript. For fast prototyping and fine-tuning, TensorFlow.js maintains the model garden with pre-trained models. This project adds the implementations and demos of three architectures for semantic segmentation, image classification and text detection.
Plans
The original goal was to add five new low-power, high-accuracy applications controlled via an interactive dashboard, providing a proof of concept for the mobile-first paradigm of machine learning.
After the sync with the core TensorFlow.js team, the project scope then was narrowed down to align with the promise of tfjs-models:
- Consider practical needs of the community first, and pick suitable models later, trading accuracy for speed and size
- Bridge the gap between the jargony machine learning world and JavaScript app developers, widening the involvement
- Provide zero-config APIs with easy access to the low-level tooling
The tfjs-examples module is similar in form to tfjs-models: both show the capabilities of TensorFlow.js with demos and implement overlapping models. Nevertheless, they are different in spirit: while the tfjs-models repo serves as a convenient toolbox providing off-the-shelf building blocks, the tfjs-examples repo is a starter kit for personal projects.
The model garden cannot capture all of the use cases, striving instead to make fine-tuning as easy as possible. Since some models, like MobileNet, are more suitable for re-training than others, like Pix2Pix, the ones with the larger minimum viable audience are given priority.
Models
DeepLab: making sense of the infinite content
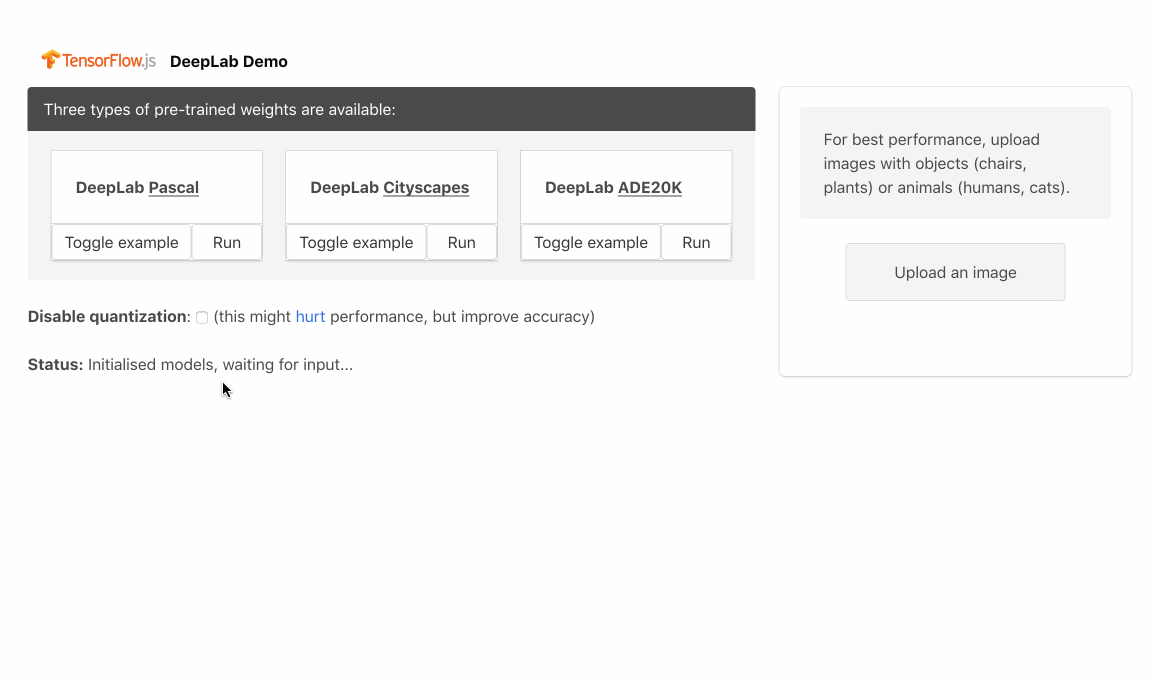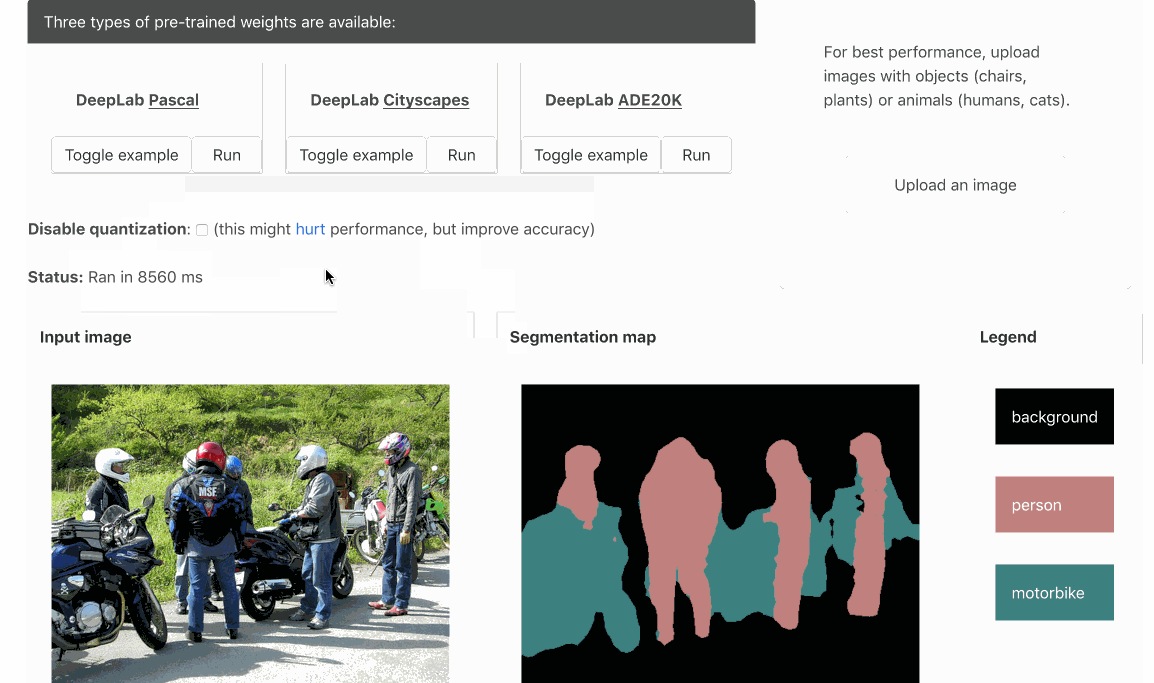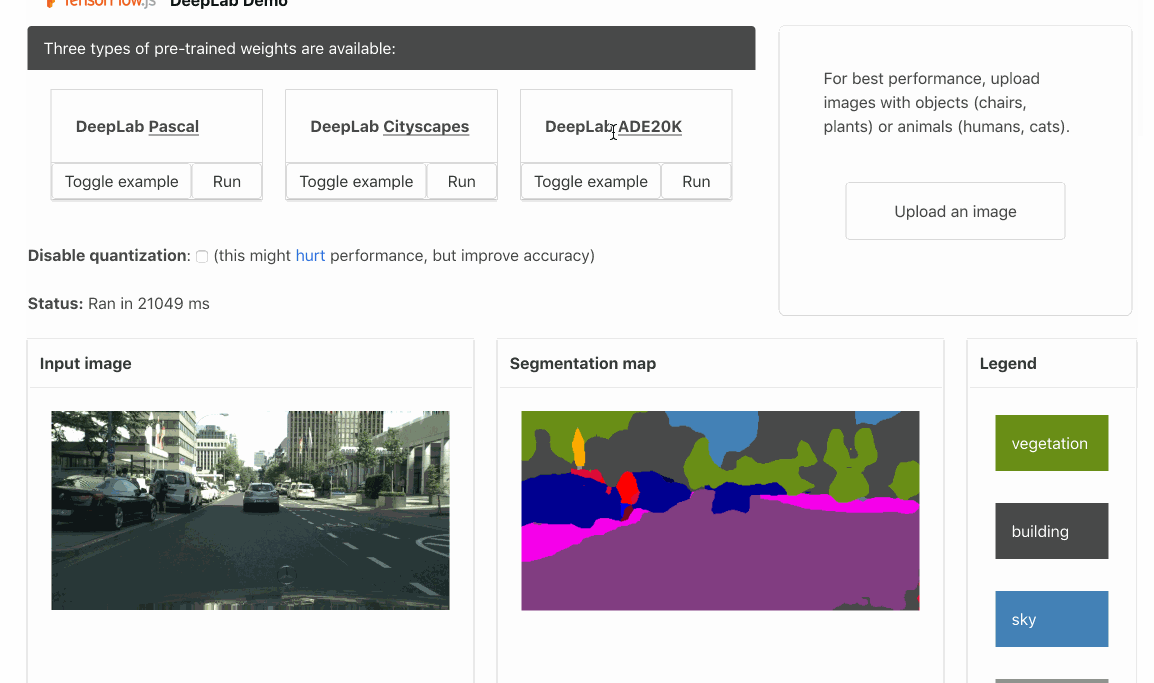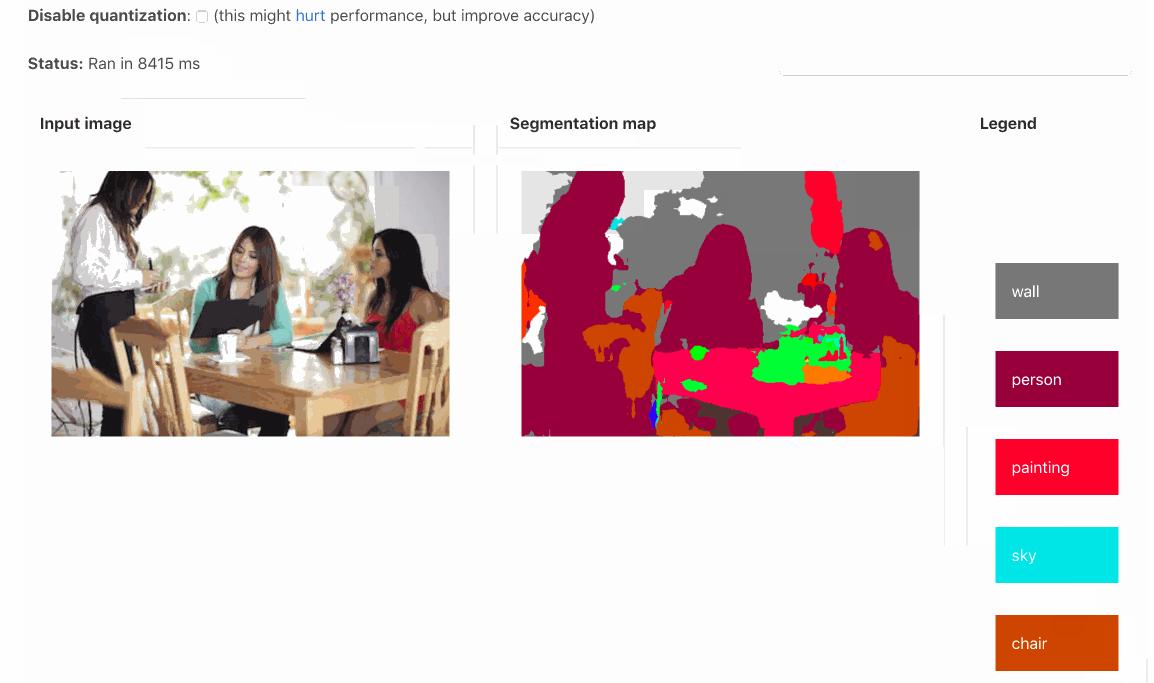
Pull Request | Demo | Usage | Conversion Script
DeepLab assigns a semantic label (a human, road, Harley-Davidson, and so on) to each pixel of the input image. Three types of pre-trained models are available:
- Pascal (21 labels)
- Cityscapes (19 labels)
- ADE20K (151 labels)
Despite the fact that CityScapes recognizes the least number of objects, it is the slowest and most compute-intensive model of all three variants. This is a known bug which is yet to be resolved.
Applications
- medical: identification of healthy and cancerous cells from CT scans
- geographical: early detection of forest fires
- artistic: low-cost CGI overlays
EfficientNet: porting a heavyweight sibling of MobileNetV2
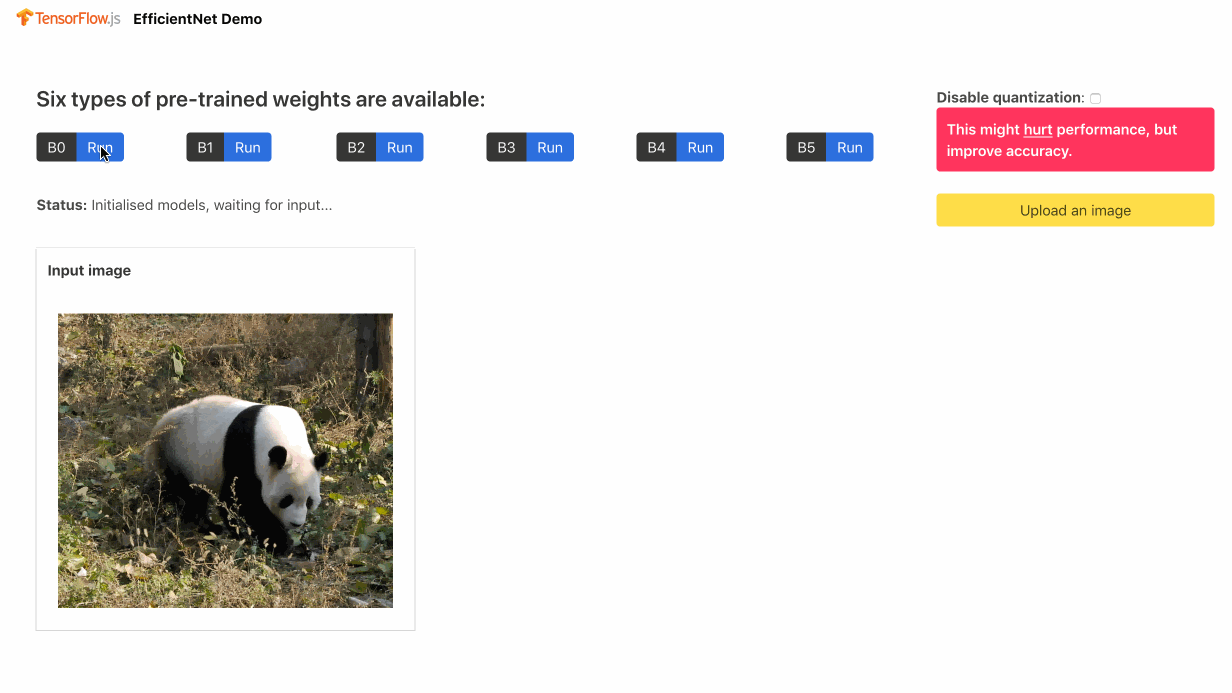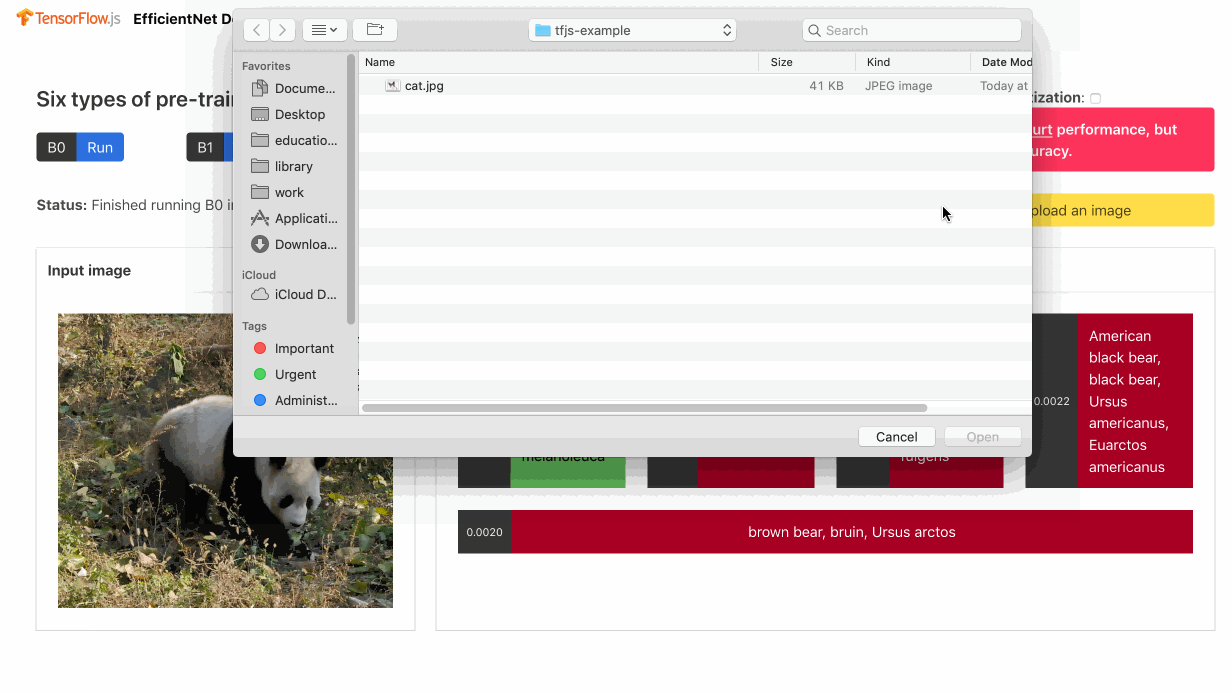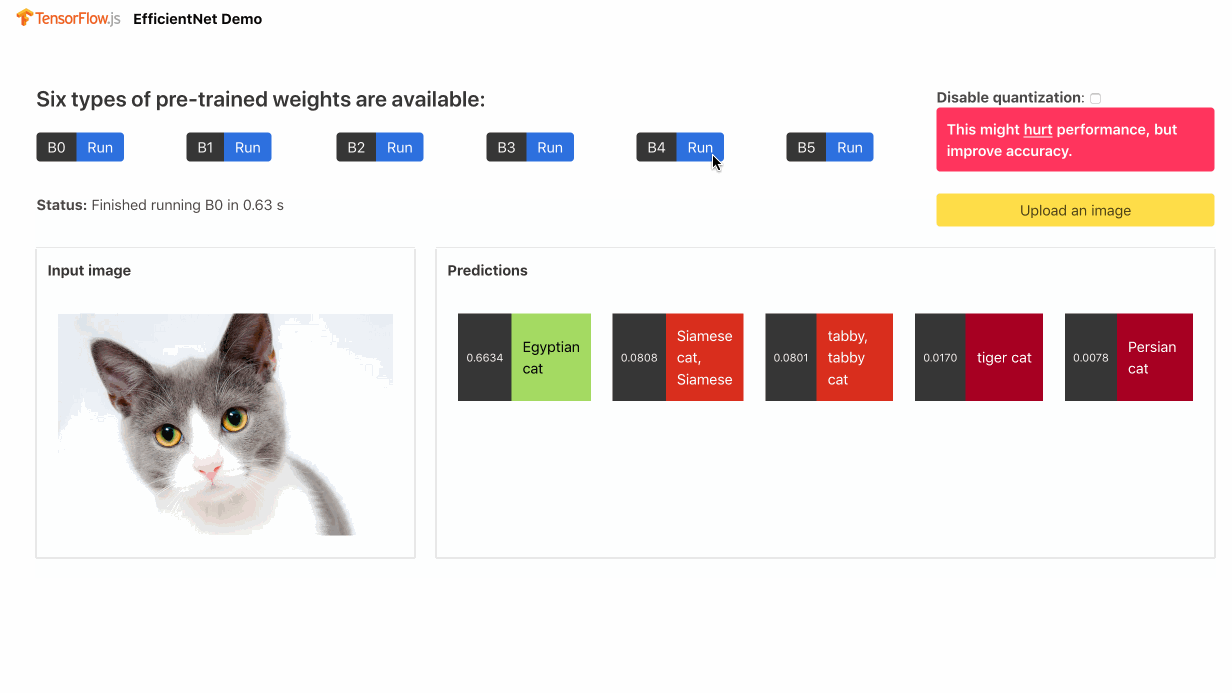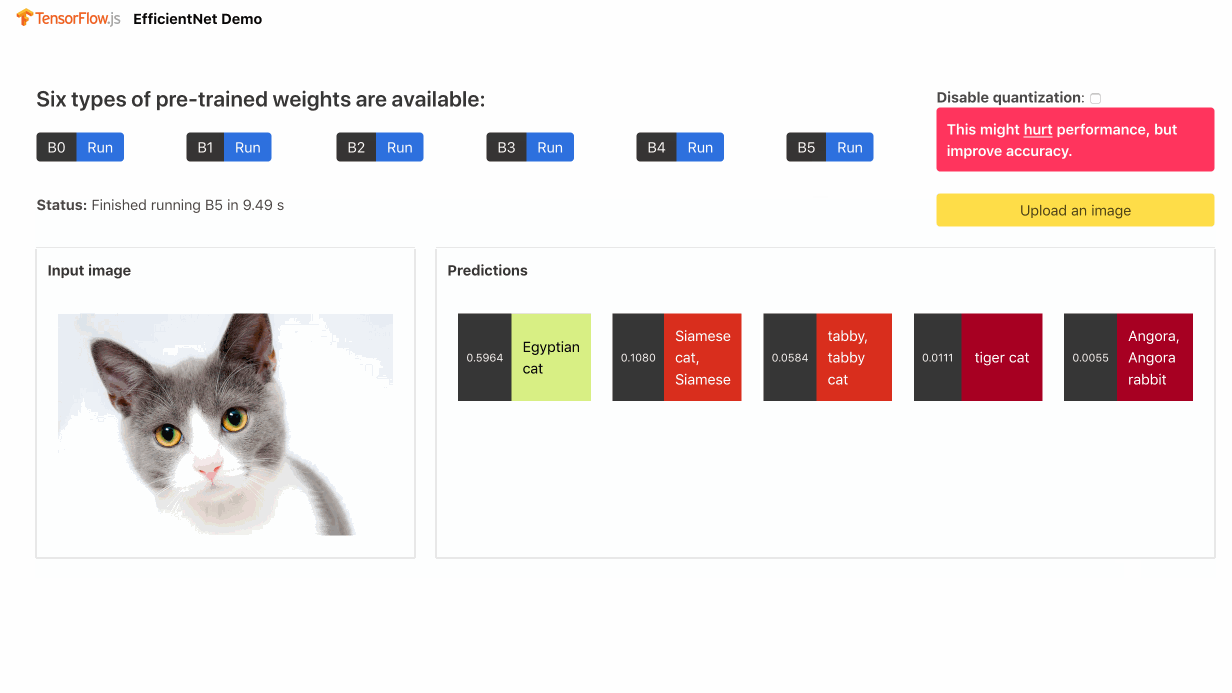
Pull Request | Demo | Usage | Conversion Script
EfficientNet classifies images into 1000 ImageNet classes, building on the success of MobileNet.
Despite the greater accuracy than other alternatives focusing on mobile platforms and a lot of excitement around its release, the model did not pass the quality assurance tests of tfjs-models: even B0, the lightest variant of EfficientNet, is slower in-browser than MobileNet.
When the full WebGPU API support comes to TensorFlow.js, a factor of magnitude improvements in performance might allow offering heavier, more accurate models as a viable alternative to the existing solutions.
Converting EfficientNet from the pre-trained checkpoint revealed a bug in tfjs-converter, brought by breaking changes associated with the upcoming TF 2.0 release. This might have been resolved by the recent updates, but further testing is required to identify the source of the issue.
Applications
- agriculture: automated sorting of the produce into grades
- retail: visual search of similar products
- marketing: adaptive ads reacting to customers wearing specific brands
PSENet: detecting text with arbitrary shapes
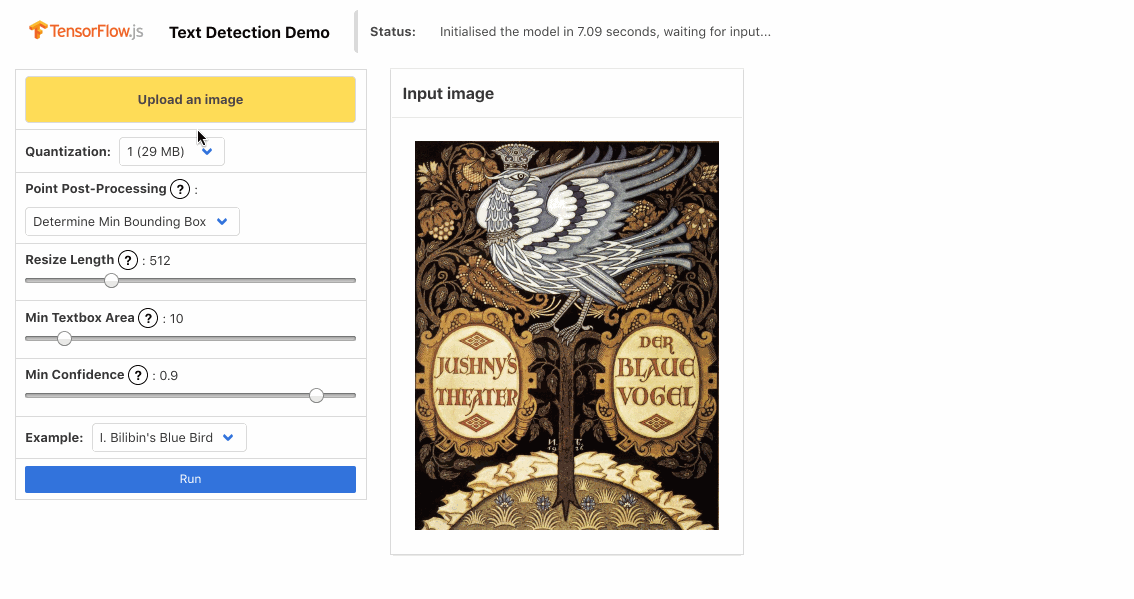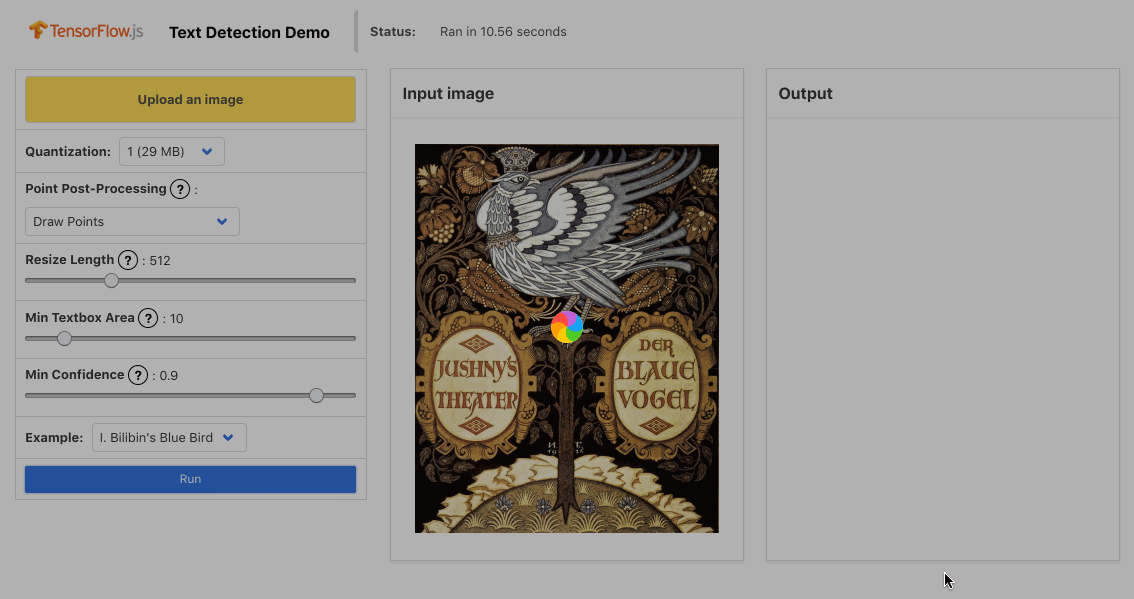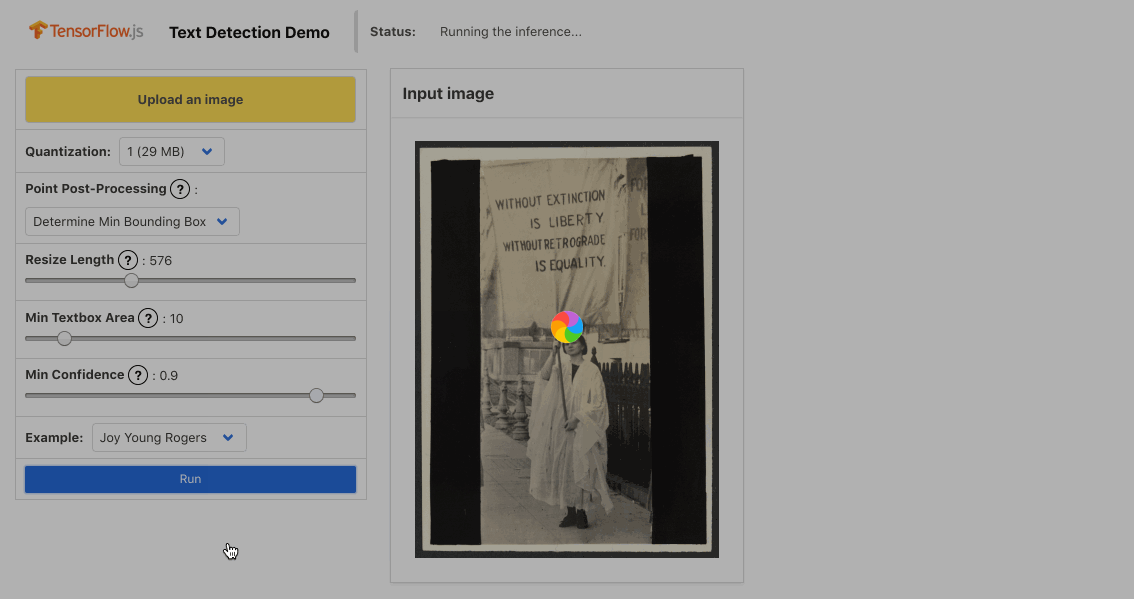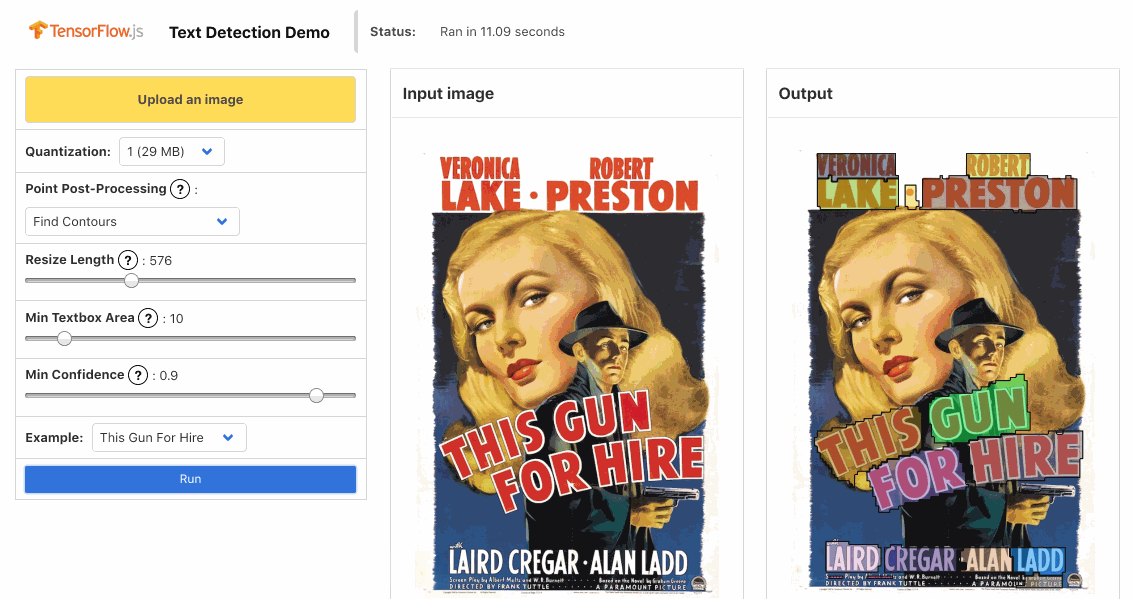
Pull Request | Demo | Usage | Conversion Script (tf.keras) | Conversion Script (tf.slim)
PSENet detects text by first feeding the image through feature pyramid network extracting features from the image classifier lacking the top dense and activation layers, applying the progressive scale expansion algorithm to extract pixels that most likely correspond to text regions, separating them into distinct components, and then reducing the components to bounding boxes.
Two non-trivial post-processing methods are available out of the box:
- Find a minimum area rectangle enclosing the component
- Determine the convex hull of the region
The demo also supports drawing contours via the OpenCV.js library, reduced in size from 9 to 2 MB using a custom build.
The progressive scale expansion algorithm is written in pure TypeScript to take advantage of the JS engine optimizations and avoid the overhead associated with the TensorFlow.js implementation details.
The model is available in two variants:
-
Ported using the
tf.slimpre-trained weights by Michael LiuThe GIF above demonstrates this model.
Check out the commit
4d963c4to load the appropriate weights together with corresponding pre-processing and post-processing methods:The model size is 115 MB non-quantized, 59 MB quantized to 2 bytes, and 29 MB quantized to 1 byte, while the inference time is 7-10 seconds on average.
-
Adapted from the PyTorch implementation by the original authors
This is the primary supported variant.
Since the inference time and model size disqualified the vanilla PSENet from the model garden, the second part of GSoC focused on optimizing text detection for mobile inference. The PyTorch implementation of the model from the original authors promised to improve the quality of predictions with 3 major differences in the approach from the
tf.slimvariant:- the feature pyramid network learned to output 7 segmentation maps instead of 6. The first of them is used as both the scoring filter encoding the likelihood that any given pixel is text, and the primary text location map masking the other 6 kernels.
- online hard example mining is applied to improve robustness of the learning process
The switch to a more lightweight FPN with MobileNet, not ResNet 50 as the backbone, reduced the raw model size by the factor of magnitude, from 115 MB to 16 MB.
After 185 attempts on the AI Platform to make training work, the results, however, looked more than strange. Despite the train loss and metrics improving as expected, validation results were disappointing, showing that 30 to 40 epochs were not enough to learn even the simplest of examples. At this point, the realization came that the problem was much deeper down the stack.
Inputs
| Sample input | Sample label |
|---|---|
 |  |
The culprit was pinned down to the tf.estimator-based setup and resolved for the final, 186th AI Platform job by re-writing the pipeline using only the machinery of tf.data and tf.keras.
Outputs
tf.keras.Model converted to tf.estimator | tf.keras.Model in the tf.estimator model function | tf.keras implementation |
|---|---|---|
 |  |  |
Despite the weight improvements and good validation performance (0.98 accuracy, 0.99 precision, 0.99 F1-score on 2000 images), several pipeline design decisions prevented the new model from beating the results of the tf.slim version:
- to speed up training, no on-the-fly random augmentations improving the performance on rugged and rotated text were used
- the backbone of the feature pyramid network was MobileNetV2 with alpha 1, which might have added too many performance-taxing nodes to the inference graph, barring the resize length values larger than 352 and thus limiting the quality of predictions
Some examples behave well...
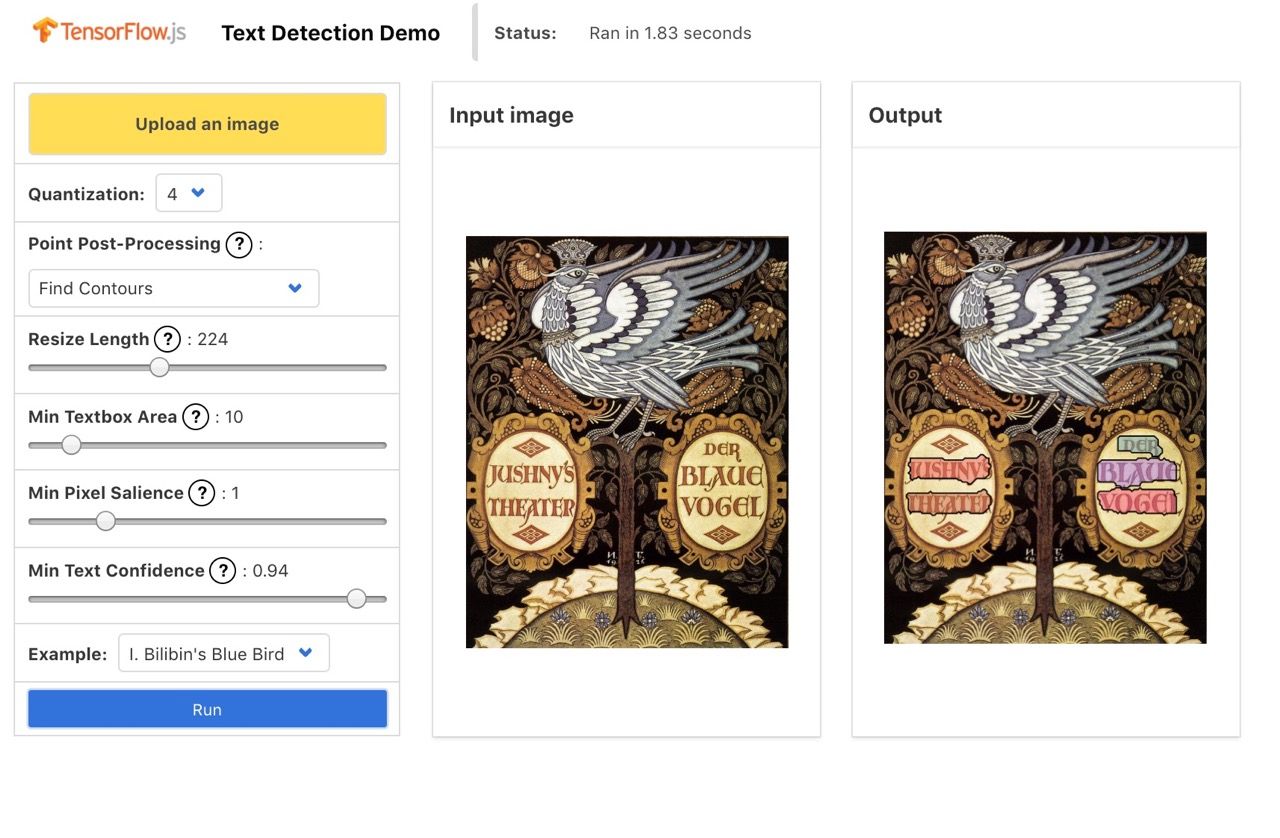
And some miss important features...
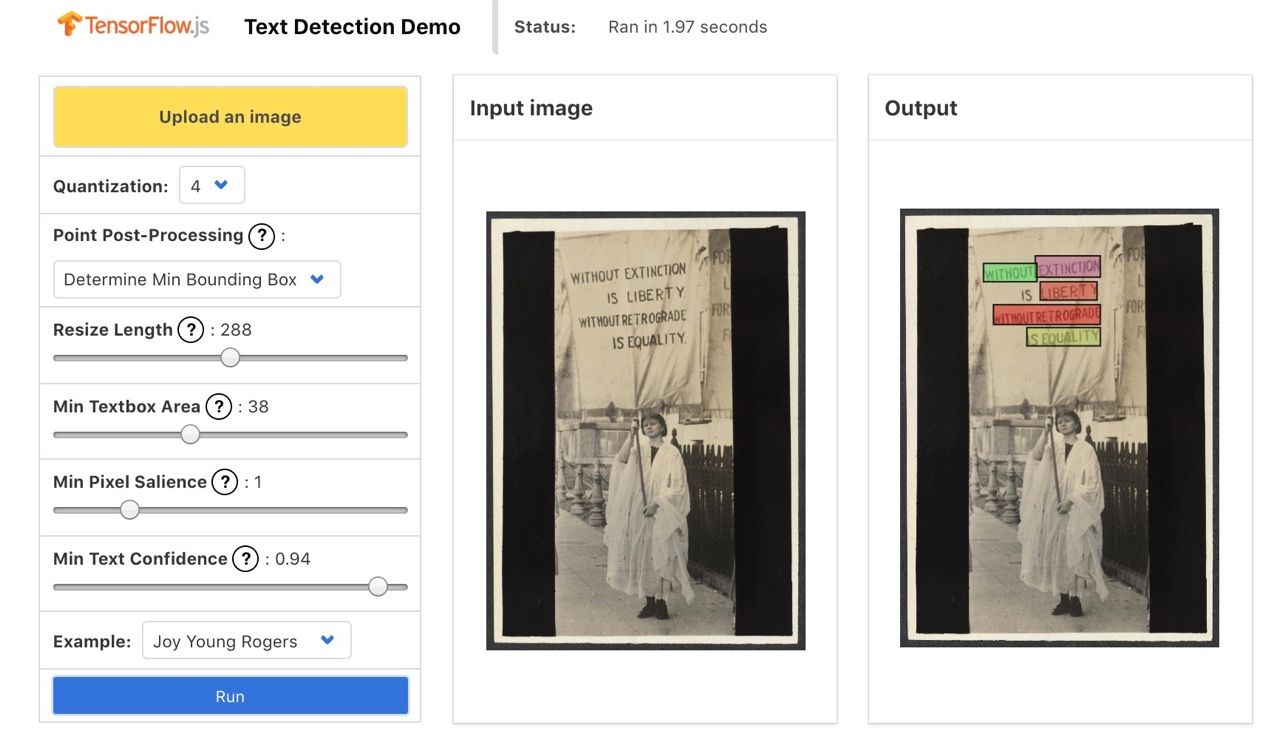
While others show the imperfections of training beyond any doubt.
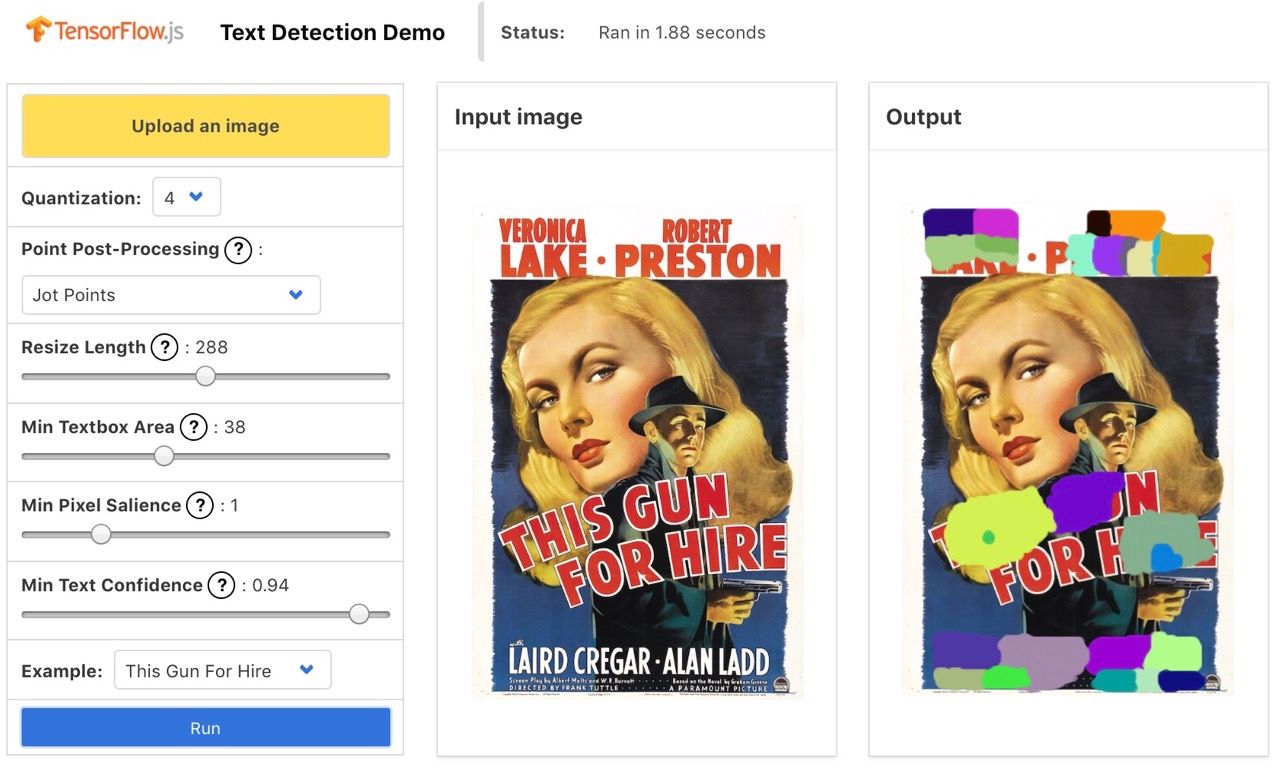
Despite these hurdles, PSENet offers a promising approach for in-browser text detection, and the TensorFlow.js port will be finalized when the weights are updated.
Applications
- privacy: masking of sensitive text information from photos
- education: extraction of text written on whiteboards
- knowledge management: detecting key parts of architectural drawings for automated annotation
Avoiding the pitfalls
Adopting the following heuristics would have helped to avoid a lot of the timesinks in the development process:
-
Check the training setup early
Overfitting on a single batch is a simple and effective way to spot problems early, since they may come from unexpected places not necessarily reflected in stack traces or loss anomalies.
Andrej Karpathy gives this and other advice in his recipe on training neural networks.
-
Maintain a reproducible development environment
The code with a lot of dependencies breaks often, and if it works fine now, it might be impossible to say how in two weeks. Freezing dependencies in the virtual environment after successful deployment reduces the pain of starting anew for someone else (which might as well be yourself).
-
Take a chance on the bleeding edge software before the major release
Upgrading to the TensorFlow 2.0 resolved cryptic problems with warm-starting
tf.kerasmodels and could have eliminated the issues withtfjs-converterandtf.estimator, which had features propagated down from the TF 2.0 beta releases.
Future Work
- Train PSENet on a larger dataset with data augmentations and support MobileNetV2 with alpha less than 1 as a backbone, polishing the model for a merge
- Port MORAN to complete the TensorFlow.js OCR stack
- Experiment with converting the Cityscapes variant of DeepLab from the checkpoint, not the frozen graph to avoid performance issues
- Resolve the EfficientNet converter issue
- Document end-to-end model fine-tuning for DeepLab
- Add B6 and B7 variants of EfficientNet and publish the model to NPM as
efficientnet-js
Other ideas for growing the model garden are collected in the scratchpad.
Links
Porting the models called for contributions to the TensorFlow.js ecosystem and beyond.
The list below highlights all of them.
- Issues
- OpenCV.js: building a lightweight version of OpenCV for the browser
- Terser: mangling the TensorFlow.js code with ES6 features
- TensorFlow: fixing the interplay of
tf.estimatorandtf.dataon AI Platform - TensorFlow.js: improving the developer experience
- TensorFlow Models: adding support for more variants of DeepLab in the public demo
- Pull Requests
- Keras EfficientNet: making the code reproducible and compliant with the law
- TensorFlow.js Converter: fixing and giving advice on the dependency management
- TensorFlow.js Models: recognizing objects and text in images
- Repositories
- PSENet: optimizing text detection for mobile devices
- MORAN: porting text recognition for in-browser transfer learning
- tfjs-model-starter: aiding the implementation of new TensorFlow.js models
Acknowledgements
I am grateful to the following amazing people for the gift of a valuable learning experience that GSoC has become, helping me grow into a pro and making the world a better place:
- Paige Bailey, for being a compassionate and super-supportive TensorFlow mom
- Manraj Grover, for mentoring and giving indispensable feedback
- Yannick Assogba, for sharing the vision and having illuminating discussions
- Daniel Smilkov, for the inspiration from the earliest days of GSoC
- Nikhil Thorat, for nimble trouble-shooting of the converter
- Pavel Yakubovskiy, for building segmentation-models and offering help with FPNs
- Alexey Ozerin, for giving advice on distributed training and hyperparameter tuning
- Julia Gusak, for explaining compression techniques and ConvNet tricks
- Dan Oved, for teaching the best practices of building TF.js models
- Evgeny Sokolov, for helping balance GSoC with the university requirements
- ODS.ai, for a welcoming community of data science experts